The base of our demand generation activities
The base of our demand generation activities
Account segmentation and prioritisation becomes an important aspect especially for outbound sales team, as they embrace account based marketing

A key part of our GTM plan was around qualifying our universe of accounts. As we moved upmarket (as referenced in my last post), and investing in our outbound sales team, it became important that we qualified our accounts well. This would serve as the base of our entire marketing strategy.
Our tech stack:

The idea was to have a universe big enough for us to have enough leads to last us atleast 4 quarters ahead (given the current product offerings).
This required us to do 2 things (and in that order):
Segmentation Logic: Who to go after
Prioritisation Logic: When to go after
The segmentation logic was to qualify accounts into our universe of MQA (marketing qualified accounts). And the prioritisation logic helps to well, prioritise accounts, to help our sales teams reach out in the order of their willingness to buy.
For segmentation, after a lot of ad-hoc process, we ran this via our internal tool that we created called Sherlock. Sherlock was the platform that constantly interacted with Salesforce (our sales engine) and Hubspot (our marketing engine) and had a 2 way sync, to send the updated data back into these systems.
Learning: Your demandgen stack is going to evolve as you grow as a company and often off the rack solutions might not always work.
For segmentation at Belong, we needed our customers to be doing a minimum amount of mid to senior level hiring in their engineering organisation for our product to make sense to them. This was an important metric to track (we looked at last 1 month jobs posted + last 12 mo. hiring as a proxy) and was a much reliable indicator instead of just “company size”.
Basis all of these we were able to break account further into mid, large and super large. Note: However, the cut-off criteria for segmentation into mid/large/super large differed for each of the 4 major industries (Tech incl. captives, ITeS, BFSI, Others).
Looking back, this was the easier part (though there are operational challenges while trying to do this, like company name standardization, which I won’t delve into in this post). The harder part was the prioritisation logic.
Why?
In a predominantly outbound engine, the efficiency of the sales org depends on the hit rate. We wanted to ensure that our SDRs had a high SQA:MQA ratio and timing plays a big role here. Hence the prioritisation logic took into account a bunch of factors which were periodically updated. Some of these factors were:

Each of these were specific to our business. The idea basically is that incase your MQA universe isn’t infinite (as was a case with us), you want to ensure that you’re using the next proxies to ensure that you’re touching the most likely accounts to convert first. Esp in enterprise business, having a nuanced view of the universe (esp once you start having 5+ SDRs) makes sense. We had to create this system because none of the existing data tools like D&B, Insideview etc were able to give us a distilled view.
This focus on data, helped us increase our MQA:SQA ratio in the 50-60% range.
Side note: Revenue / Employee (benchmarked to an industry’s average) was an interesting metric that became crucial for us. It gave us a quick and dirty proxy for how much an employee was “worth” to the company. Company’s with higher Rev/Employee ofcourse would be more open to investing in cutting edge talent acquisition solutions. This was a MUCH better proxy than just revenue. It was important to calibrate for industry norms here however. For example a rev/employee of $100K/employee for Software Product companies isn’t too good, but is a great number for software services, with the best in breed ITeS companies coming up here (think Thoughtworks etc). So equipping our sales people with this vital info helped them prime for a good entry price to consider to know whether there was scope to get a larger deal.
Learning: In the enterprise context, especially important to find enough proxies (often not readily available with off the rack solutions) that help you prioritise your ideal prospects to help save the Account Executive’s time eventually.
All this uptil now was still just the firmographic data (which was obtainable via secondary research).
On top of this, we layered data from our marketing and sales team around engagement levels, to answer the question “Is this the right time”
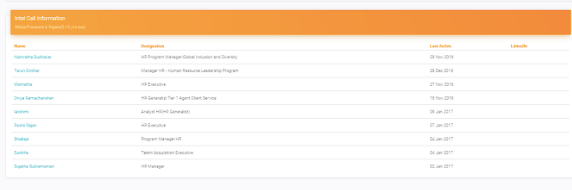
This meant integrating data from our events, content, outbound prospecting, webinars and the CXO relationships that we maintained, back into sherlock. We even added an extra alerting system to let us know if an existing user/buyer of the product changed companies. In addition to this, we had an account map charted out for each company which was eventually used to create detailed account maps, as well as track how many folks did we meet in the account, which I had covered in my previous post.
Learning: For whatever reason, if you find yourself in a market with limited leads, your sales & marketing team has to work closely to figure “when” is the right time to sell, and nurturing accounts becomes a core strategy, because you can’t just say “we lost a deal”, since you’ll be out of accounts to sell to.
Putting it all together
Sherlock, our internal sync and data engine (built by Adi, who I worked with extensively for growth initiatives) that was mentioned below finally helped bring all of this together to help marketing and sales orchestrate our execution. The first sheet at every sales person saw was the one below, which had their list of accounts, along with a score and some key parameters.
They further drill down to any account and get macro as well as specific data about the company, in a time series manner (job postings, headcount, major talent flows at c-level) as well as key news items.
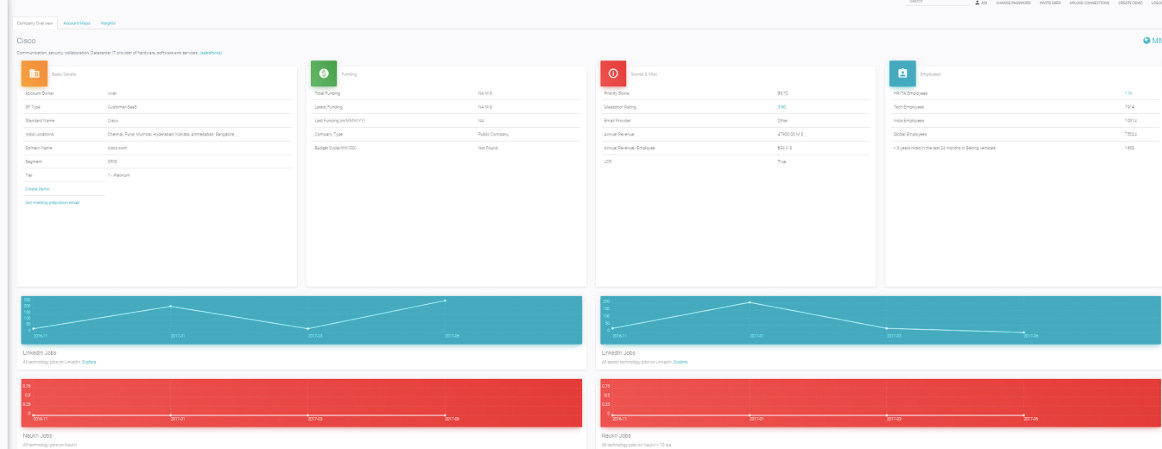
And finally, an account map (this was a 2 way sync between hubspot/salesforce and sherlock), to give an idea of who all have we connected with in the past and the folks we need to connect/re-connect with.